Odaseva Zero-Copy Data Sharing for Databricks
Fuel your lakehouse with live Salesforce data products.

Open Architecture
Eliminate vendor lock-in by leveraging open Delta Sharing. Turn any Salesforce data into a portable resource, ready to be securely consumed by any compute engine, anytime, anywhere.
Frictionless Data Ops
Deploy managed data products. Reclaim engineering time with a service that handles Salesforce schema drift and complex object relationships automatically.
Unbreakable Data Boundaries
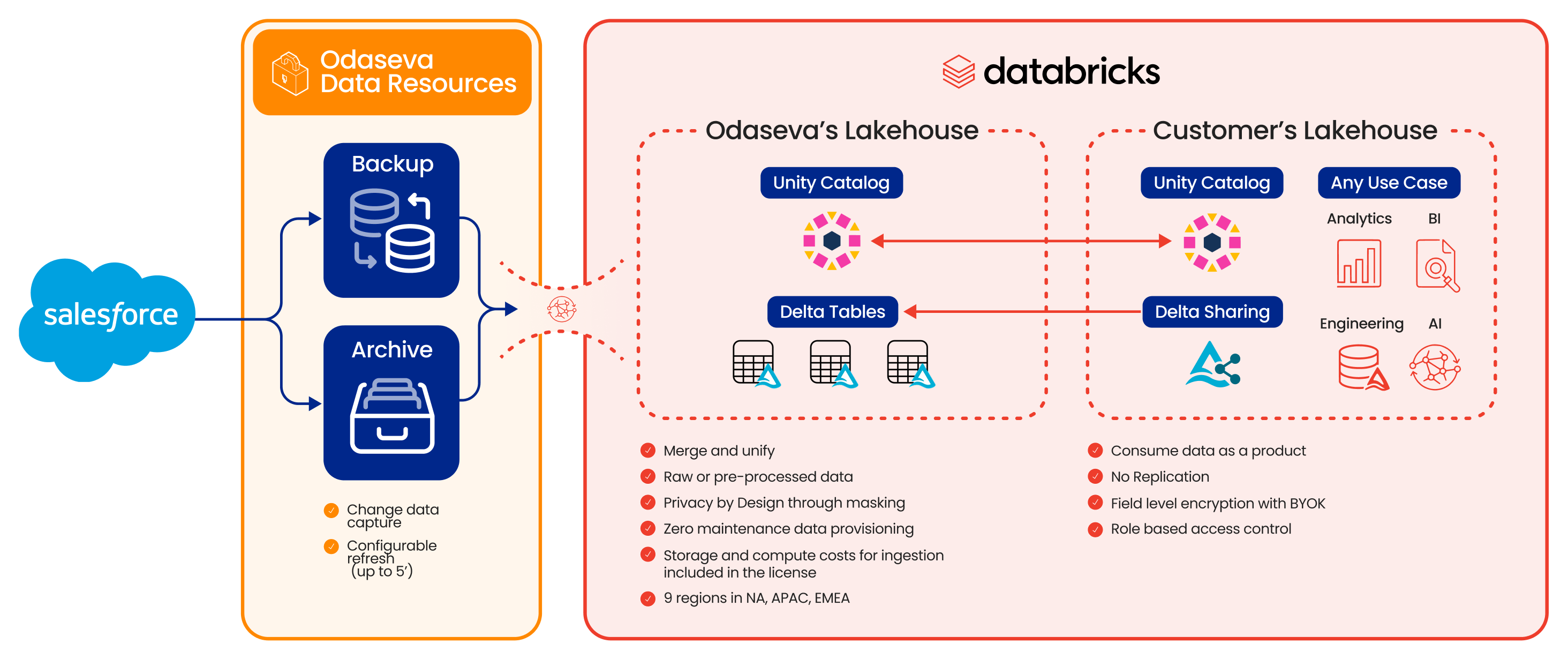
Access the totality of your Salesforce schema, archives, and field history from day one. By repurposing backup and archive streams, we activate your customer data without engineering delays.
Unified Security & Governance
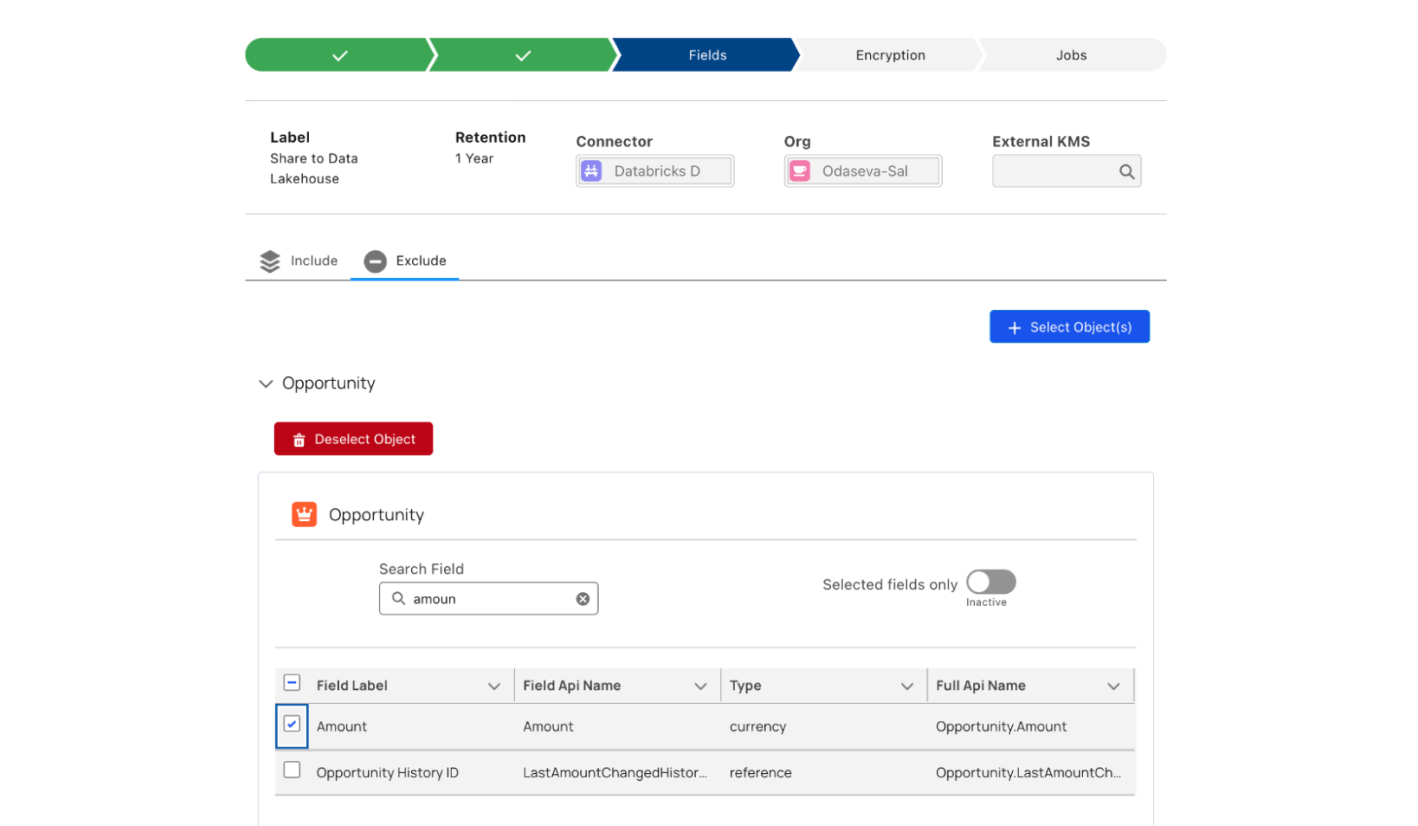
Maintain absolute control over your customer data. Enforce Zero Trust security, field-level encryption and masking natively within Unity Catalog, while keeping your CRM data immutable.
Why Odaseva Zero-Copy Data Sharing for Databricks?
Bypass your data volume limits. Engineered for the world’s largest Orgs, our zero-copy bridge provides instant data visibility and outperforms standard Salesforce API limits by orders of magnitude.
Stop paying data taxes. One fixed fee activates your entire Salesforce scope for AI and analytics.
Achieve a zero-impact architecture. We uniquely repurpose backup streams into live, read-only data products to eliminate the extraction burden on your Salesforce production Org.
Turn cold archives into AI fuel. Offload historical data to keep Salesforce lean while ensuring your Lakehouse retains the historical context required for high-fidelity model training and Agentic AI grounding.
Personas
Revisit Your Data Architecture for Next-Gen Data Products
Architect zero-copy data products using Delta Sharing and Unity Catalog to fuel the Databricks Intelligence Platform with complete customer context.
Reclaim Time, Build More Value
Shift from fixing pipelines to delivering AI-ready data products within Unity Catalog to fuel high-fidelity machine learning models.
Drive Autonomous ML Discovery
Independently access the full set of Salesforce data products in Databricks and Mosaic AI to discover predictive signals and ground AI models without infrastructure bottlenecks.

Scale AI, Reduce the Data Debt
Remove frictions to connect data to measurable business impact and fuel the Agentic Enterprise at scale.
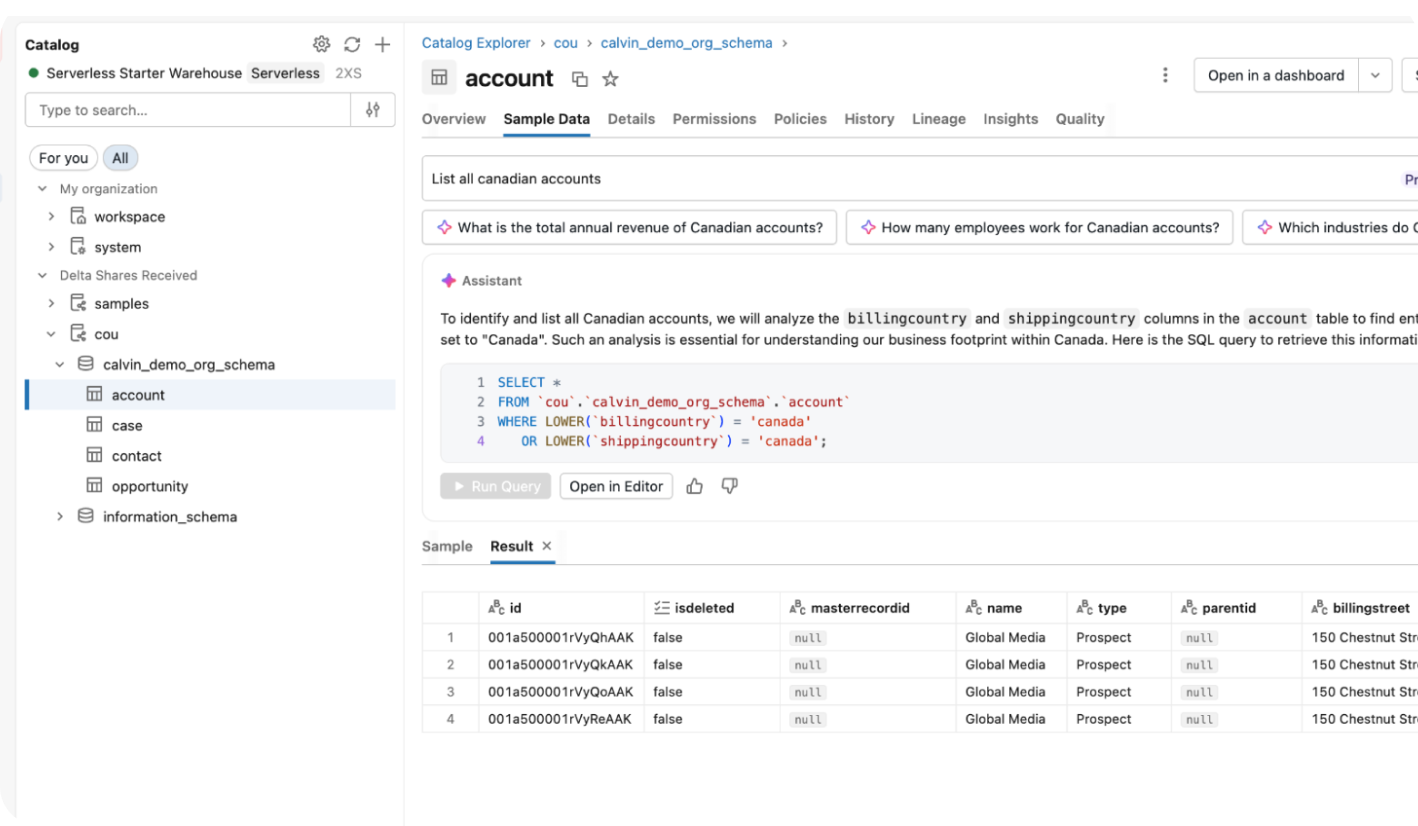
Activate Salesforce Data, Instantly
Break the CRM walled garden by making Salesforce data a first-class citizen in your AI and ML roadmap.
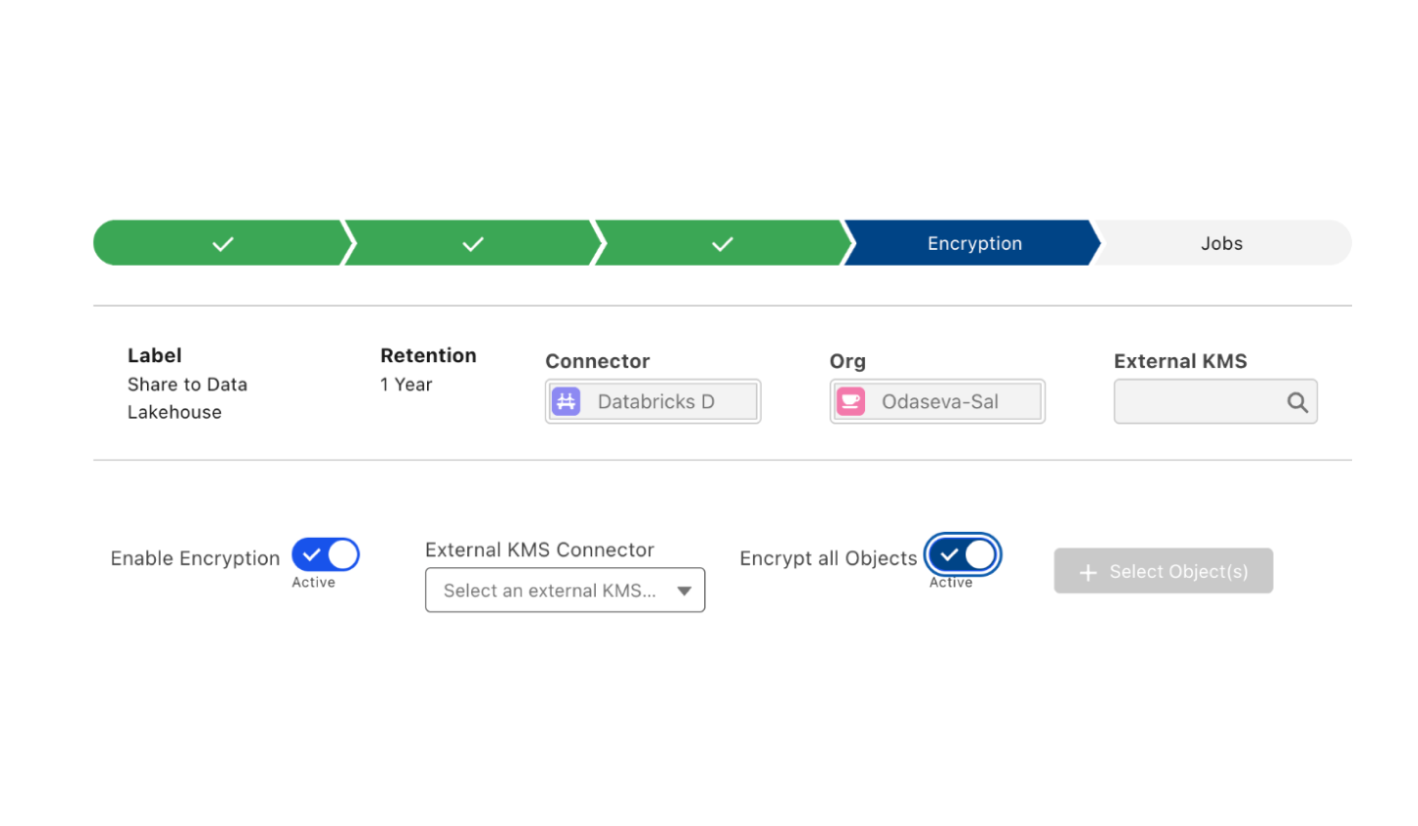
Enforce Trust, power AI Innovation
Establish a secure, governed passage for data sharing to enable AI innovation through centralized Zero Trust controls
FAQs
Traditional ETL tools act as pipeline plumbers, constantly fighting Salesforce API throttles and manual schema mapping. Odaseva flips this model by treating Salesforce data as a managed data product. We repurpose your existing backup and archive streams, bypassing API bottlenecks to deliver high-fidelity data directly to your lakehouse. This removes the pipeline maintenance burden on your engineering team, as we handle extraction, format uniformization, and complex object relationships as a managed service.
Performance bottlenecks in Salesforce integration usually occur at the extraction layer. Odaseva decouples extraction from consumption by preparing data in a secure, Delta-optimized vault first. Our architecture is engineered to outperform standard Salesforce API extraction limits by orders of magnitude, ensuring that even for Orgs with billions of records, your AI models and analytics dashboards never choke on data growth or physical movement latency.
The process is manifest-driven and utilizes the open Delta Sharing protocol. We ingest your secure Salesforce backups, convert them into optimized Delta Lake tables, and register them in your Unity Catalog as a Foreign Catalog. These "foreign tables" can be directly queried by Spark or Photon, consumed by Mosaic AI and autonomous agents, or used as the landing zone bronze layer within a larger Medallion Architecture—all without the latency or cost of Salesforce to Databricks physical data movement.
No. This is a fundamental advantage of our architecture. Because we uniquely reuse your data resilience streams (backups and archives), the activation process triggers zero additional calls to the Salesforce API for consumption. This protects your Salesforce production Org from the performance degradation often caused by heavy AI queries or high-frequency extraction, effectively maximizing your integration ROI by freeing you from expensive API dependence.
We employ a Zero Trust architecture that aligns with global data protection principles. Data remains privacy-compliant through end-to-end encryption with Bring Your Own Key (BYOK) support for your most critical datasets, providing absolute sovereignty over sensitive fields. For broader organizational needs, irreversible data masking and anonymization can be applied across all shared data products. Because the bridge is read-only and the underlying data is immutable, we ensure your primary Salesforce source of truth remains pristine and compliant while safely fueling Agentic AI and Mosaic AI workloads.
Because Odaseva is a Salesforce Data Resilience platform, handling API limits, schema drift, and SaaS outages is our core competency, not an afterthought.
Our architecture is designed to automatically detect throttling, handle retries, resolve silent sync failures, and resume extraction without data loss. Since we deliver data as a product, monitoring and resolving these interruptions is part of our managed service. If a disruption occurs, our team and automated systems handle the resolution and backfilling behind the scenes—ensuring you receive a reliable stream without ever having to debug a failed job.
Key resources

Empowering Scalable, AI-ready Data Ecosystems with Odaseva Data Edge

Modern Architecture for Data at Speed and High Availability

3 Steps to Secure Your Data in an AI-Automated World

